

Intel’s “Xeon Scalable” range is designed to compete directly with the AMD Naples platform. Naples is a high-performance server platform that relies on multi-core linking through AMD Infinity Fabric Interconnect. This new AMD processor has given Intel some challenges regarding how to structure its high-core family. And has led Intel to the creation of a new mesh-based interconnect technology.

To link multiple cores together, Intel traditionally relied on its Quick Path Interconnect (QPI) Interconnect. But has it’s limitations while doing that. To begin with, QPI is a point-to-point technology. And it is intrinsically unsuitable to link cores to each other in a mesh topology as needed when random cores want to target each other. To work with it, you would have to create a QPI link from each core to every other core of the CPU. And that would be a total waste of resources.
Historically, to solve that problem, Intel has used a two-way “Ring bus,”. Basically, when transmitting data, it must be passed around the bus. On each clock cycle, the bus can change data in one way or another. But if you want to go from one core to another as far away as possible, latency suffers. Which is not feasible for a high number of cores.
Introduction Mesh Interconnect:
Technically, this new Intel Mesh Interconnect technology was introduced with Xeon Phi Knight’s Landing processors. But they are quite expensive CPUs. Now, in simpler chip implementations, each core has a direct connection to each neighbor chip. That is a full mesh topology with all its benefits. In more complex CPUs, this direct link is again uneconomical. Since it would require a lot of resources so that any chip manufacturer will implement professional CPUs like Naples and Xeon Scalable. Instead, we will return to a simpler mesh topology, rows, and columns.
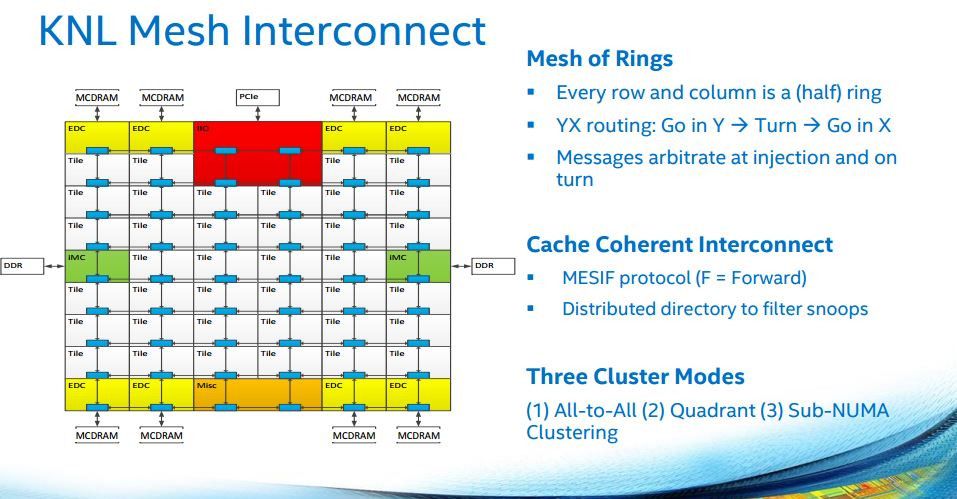

Mesh Interconnect Grid Routing System
It is a grid with a complete XY routing system. And this means that instead of circling a huge circle in the form of a bus, they can go through a much more compact “cubic” topology and save time. In a simple 3 × 3 cube example, whereas a total of 8 clock cycles would be required in an equivalent ring bus. So that the communications reach the farthest cores. While the maximum number of core based on mesh interconnection is 4.
The bottom line is that Intel has an interconnect that can compete with AMD’s Infinity fabric. The mesh interconnection will come in the Xeon Scalable and Skylake-X enthusiastic markets.